
“Three months ago, at NeurIPS 2019, we presented a robust 8-bit platform that toppled the 16-bit barrier for deep learning training while fully preserving model accuracy. Today, we’re very excited to be sharing new results that push the envelope for deep learning inference, enabling model deployment to work with high accuracy down to 2-bit precision.
IBM Research has pioneered the pursuit of reduced precision and approximate computing techniques. In the 2015 seminal paper at the International Conference on Machine Learning (ICML), we demonstrated a quadratic improvement in performance efficiency by reducing precision from 32-bit to 16-bit for both training and deployment. Our approach has been broadly adopted, while we have continued to lead with innovations in approximate computing and to push the boundaries of reduced precision.
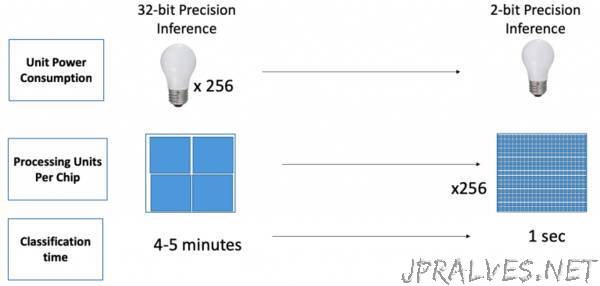
At the 2019 SysML conference, we share new results that transcend the leading edge of 8-bit precision for deep learning training: our new activation technique to create a quantized neural network (QNN) achieves high accuracy for 4-bit and 2-bit precision computations, generating multiplicative gains in performance and efficiency. These benefits translate directly to performance, power consumption, and cost for chips performing AI inferencing in edge devices, as shown in Figure 1.
Reducing precision down to 2 bits has been extensively pursued, with a wide spectrum of quantization techniques. But previous attempts have failed to match the accuracy of 8-bit or 16-bit precision hardware, particularly for convolutional neural networks (CNNs).
Quantized neural networks (QNNs) are formed by quantizing weights and activations to minimize the CNN computation and storage costs. The accuracy degradation with quantization is particularly challenging for CNNs, limited by the ReLU (Rectified Linear Unit) activation function, which inherently relies on high dynamic range and precision to capture the unbounded continuous range of activation values. Collapsing the weights and the unlimited range of ReLU-generated activations into four discrete bins, as required for 2-bit inference computations, causes large accuracy losses for deep learning inference.
In PArameterized Clipping acTivation (PACT), a maximum activation value is automatically derived for the unlimited range of activation values as part of the model training itself. This reduced, fixed dynamic range is then “quantized”, creating four discrete activation values, enabling high accuracy to be retained with 2-bit inference, as shown in Figures 2 and 3. Deriving the maximum activation value, or clipping coefficient, is incorporated in the model training cycles, without any penalty to model training times. The derived clipping coefficients are then incorporated into the deployed inference model with minimal impact to model accuracy when compared to 8-bit or 16-bit inference on CNNs.
In addition, we also introduce a novel quantization scheme for weights: statistics-aware weight binning (SAWB). The main idea in SAWB is to exploit both first and second moments of the neural network weight distribution to minimize the weight quantization error for the deep network. These statistics help the quantized states capture the shape changes in the weight distribution. Combining the PACT and SAWB advances allows us to perform deep learning inference computations with high accuracy down to 2-bit precision.
Our work is part of the Digital AI Core research featured in the recently announced IBM Research AI Hardware Center. Beyond Digital AI Cores, our AI hardware roadmap extends to the new devices and materials we are introducing in our Analog AI Cores, which will drive AI hardware leadership through the next decade, building on a common architecture and software foundation and further exploiting our algorithmic advances, such as PACT.
We present this paper, “Accurate and Efficient 2-bit Quantized Neural Networks” at SysML in Stanford, CA, today.”