
“Fujitsu Laboratories Ltd. today announced that it has developed a technology that offers both high speed data-processing and high-capacity storage in distributed storage systems, in order to speed up the processing of ever-increasing volumes of data.
Recently, customers have looked for improvements in processing speed in storage systems that handle everything up to data analysis. This is in response to a growing need in such technologies as AI and machine learning for the analysis and utilization of rapidly growing volumes of data, including unstructured data, such as video and log data. However, this requires storage systems that can efficiently analyze unstructured data stored in a distributed system, while providing their original storage functionality for data management as well as data processing capabilities. Fujitsu Laboratories has now developed “Dataffinic Computing,” a technology for distributed storage systems that handles data processing while also fulfilling their original storage function, in order to speed up the processing of large volumes of data. With this technology, storage systems can process large volumes of data at high speeds, including unstructured data, enabling the efficient utilization of the ever-increasing amounts of data, in such cases as utilizing security camera video, analyzing logs from ICT systems, utilizing sensor data from cars, and analyzing genetic data.
Development Background
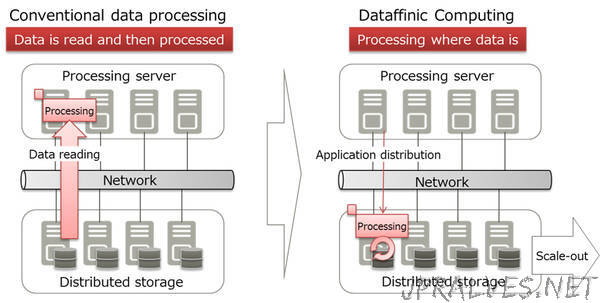
Currently, there is a developing trend of innovation and business transformation through the utilization of large volumes of data generated on various front lines. The volume of data is increasing exponentially as there are conventional structured data managed in a database, such as customer data and POS data, as well as unstructured data, such as video and log data. To efficiently use this large volume of data, AI, machine learning and other technologies are in demand to streamline analysis. Conventionally, data was analyzed in processing servers, but if data could be processed in the same systems where it is stored, it is expected that would increase the speed of data analysis processing.
Issues
Data processing requires the processing server to read the data from the storage system. As the volume of data flowing between the storage system and the processing server increases, the time required to read the data can become a bottleneck when utilizing large volumes of data. On the other hand, data processing at high speeds becomes possible when the processing is done on the storage system without moving the data. Nonetheless, this makes it difficult to analyze unstructured data distributed across the storage system, and to maintain stable operations in the system’s original storage functionality.”